

x
bbmri-eric website

I am looking for information as
Researcher
Industry
Patient
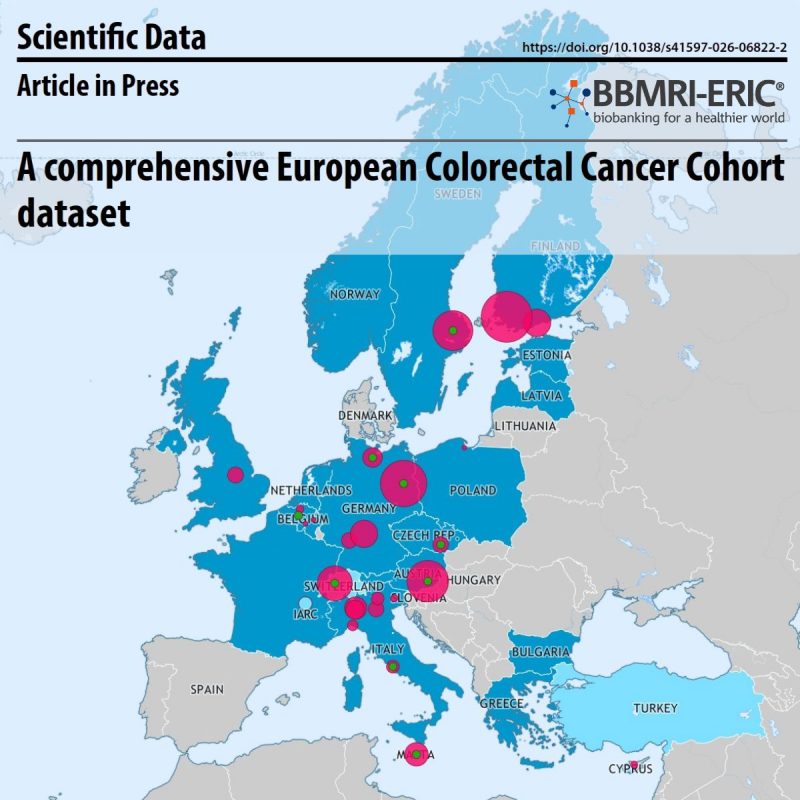
A comprehensive European Colorectal Cancer Cohort dataset
This article is 506 words and is an approximate 2.5-minute read.
A comprehensive European Colorectal Cancer Cohort dataset
“This dataset is more than a resource – it is a blueprint for the future of interoperable, FAIR, health data ecosystems”
Colorectal cancer (CRC) is a leading cause of cancer related deaths worldwide, and its global burden is expected to continue rising, reaching an estimated 3.2 million cases annually by 2040.
A recent study led by BBMRI-ERIC describes a major European effort to address this challenge by building a large, shared, dataset of CRC patients enabling new research to improve early detection and treatment.
Closing the gap
As mortality for CRC rises, one of the key challenges in the field is the lack of large patient datasets. The disease often develops slowly from initial lesions, so better data can help researchers identify patterns that may support earlier diagnosis and more effective treatment decisions.
Current screening methods range from simple stool tests to more advanced DNA-based and imaging techniques, but no single approach is perfect. Researchers are now increasingly combining traditional diagnostics with genetic markers and artificial intelligence to improve accuracy.
Despite these advances, progress in developing better tests and treatments is limited by the scarcity of large, harmonised, clinical datasets. The Colorectal Cancer Cohort Dataset (CRC-Cohort), developed under the ADOPT BBMRI-ERIC initiative, addresses this gap by bringing together data from over 10,000 colorectal cancer cases collected across 26 biobanks in 12 countries.
Protecting patient data
Health data like this are extremely valuable for research but also among the most sensitive. This dataset contains individual patient health information that could identify people if mishandled, so it cannot be openly accessible.
Under European law, particularly the General Data Protection Regulation (GDPR), such data are subject to strict requirements covering consent, anonymisation, access control and transparency in how data are used and shared. At the same time, scientific standards such as the FAIR principles (Findable, Accessible, Interoperable, Reusable) ensure that data are structured in a way that makes them usable for research while remaining consistent and well-governed.
Building the CRC-Cohort dataset therefore required addressing both technical and regulatory challenges from the start. This included differences in data quality and formats across countries, as well as strict legal and ethical requirements.
Despite technical and organisational hurdles, including varying IT capabilities and repeated data quality checks, close collaboration between experts and biobanks allowed the creation of a dataset suitable for medical research.
The resulting CRC-Cohort dataset has been registered in the BBMRI-ERIC Directory and on FAIRsharing and made searchable in a privacy-preserving manner using the BBMRI-ERIC Federated Platform.
Commenting on the achievement, Marialuisa Lavitrano, National Node Director of BBMRI.it and Professor of Pathology at Milano-Bicocca University, shares:
“This dataset is more than a resource – it is a blueprint for the future of interoperable, FAIR, health data ecosystems and paves the way toward earlier detection and more personalised care in colorectal cancer.”
Together, these efforts make the CRC-Cohort a major step forward for cancer research, offering a model for how large-scale health data can be safely shared and used to advance vital scientific work.


